
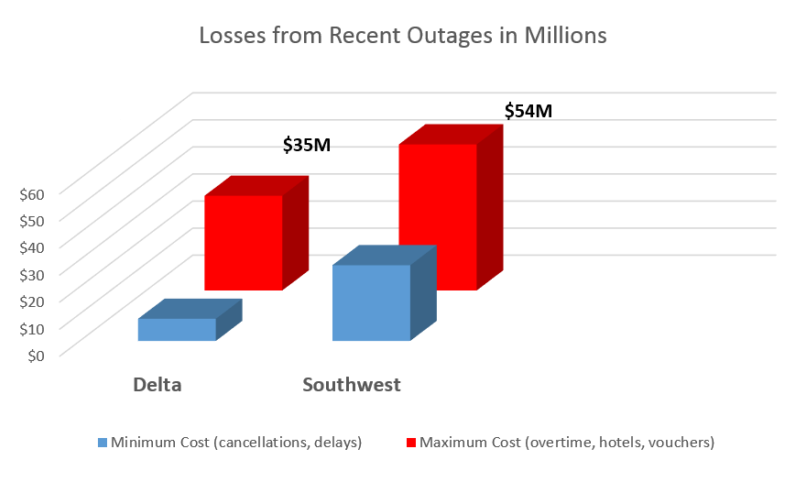
This year has been hectic for the airline industry with three major airlines suffering computer outages since January: Delta, Southwest and JetBlue. Computer outages, or downtime, can cost major corporations several thousands of dollars by the minute. Southwest Airlines CEO Gary Kelly admitted their recent outage will cost the company between $28 and $54 million. As IT people, we at Data Foundry understand everything that can break will, at some point or another. However, we took a look (as good of a look as an outsider can take) into the costs and causes of these recent outages, and our experts had a few thoughts on how these catastrophic events may have been prevented.
Delta’s Switchgear Failure
According to the Wall Street Journal, Delta’s outage earlier this month was caused by a failed switchgear, more specifically, an Automatic Transfer Switch (ATS). When a data center loses power from its main source, the UPS system kicks in to protect the critical load, and the ATS moves the load over to an alternative power source, such as generator power. When an ATS fails, staff onsite must be prepared to do their job.
Joel Reyes, Director of Sales Engineering at Data Foundry, has 18 years of experience in the data center industry. He says, “If an ATS fails at one of our data centers, our staff is trained on how to switch the power over manually. The staff is taught exactly what to do and what to expect in this situation, including details like what kinds of noises they will hear and what’s normal. The effects of failures like these can be mitigated when you have a well-trained staff at the ready.”
This particular incident caused Delta to cancel around 1,780 flights. Benzinga, a financial media site, estimates the cost from Delta’s canceled flights to be around $8.2 million based on their average sales per day. Factor in the cost of overtime, cost of hotels, and the cost is likely to be closer to $30 million, if not more.
Southwest’s Router Failure
In July, Southwest Airlines experienced a single router malfunction, forcing them to shut down their entire system and reboot. This process took over 12 hours and resulted in about 2,300 flight cancellations. The cost of canceled flights and vouchers alone totals at least $25 million, according to the Dallas Business Journal. Additional costs include employee overtime and hotel and meal accommodations for stranded travelers. This puts the cost closer to $54 million and doesn’t take into consideration the cost of reputational damage.
“When the router failed, the data … piled up like a freeway traffic jam,” CEO Gary Kelly wrote in a memo to employees. According to Bloomberg, many pilots and other Southwest employees have blamed the problem on old IT infrastructure. “The carrier’s leaders have an inability to prioritize the expenditure of record-breaking revenues toward investments in critically outdated IT infrastructure and flight operations,” the pilots’ association wrote in a news release.
Data Foundry network engineer, Phillip Carroll, had this to say about the issue, “In any network a single point of failure, regardless of how old the hardware, will come back to bite you.” He also added, “Sometimes legacy equipment is not to blame, but an outdated network design is. If Southwest used a modern and resilient design to provide a service edge in their Dallas datacenter this may not have occurred. Overall design of the network needs to be constantly scrutinized and benchmarked.”
JetBlue’s Power Outage
Back in January, a power outage at a Verizon data center during a maintenance procedure caused JetBlue’s reservation system and other customer support systems to go down. Fortunately, their systems were down for three hours and resulted in only 200 cancellations and delays rather than a couple thousand. However, three hours is a significant duration for a data center power outage.
There have been no comments from Verizon on what caused the outage, but it’s evident that their backup power failed and it’s also evident that JetBlue did not have a failover site to back up its customer support system. While we aren’t certain what happened at Verizon’s data center, we’ve reflected on the procedures we have in place when conducting tests and maintenance on power equipment.
Adrian Goepferich, Director of Data Center Operations at Data Foundry says, “At our purpose-built data centers, we have the ability to move our electrical loads to a redundant part of the electrical system with its own UPS and generator.” This prevents any disturbances as a result of maintenance procedures. He also adds, “We work according to carefully scripted Methods of Procedures (MOPs). Each MOP contains every individual action step to be performed, the expected result of each individual step, and back-out procedure to follow at different stages of the MOP. In the event that we receive an unexpected result for any individual step, we perform the necessary back out procedure to get us back to a safe condition. We do not move forward with the procedure until a full, in-depth review of the incident has been performed, the root cause of the failure is fully understood, and the right corrective action has been identified. A revised MOP with the corrected action step(s) must be approved by management before the modified procedure is allowed to be executed.”
Reflections
In conclusion, redundancy and skilled, prepared personnel are of utmost importance when it comes to complex IT systems and the data centers that house them. Every system should be analyzed for single points of failure, from networks to electrical and backup power. All personnel should be well-versed in the company’s backup and disaster recovery plans. When critical situations occur, and they will occur, it comes down to having thoroughly thought-out, specific and practiced procedures in place.
As many large companies switch over to multi-tenant data centers or colocation providers to reduce capital expenses, they should ensure that the data center that will house their equipment is well-equipped with certified staff capable of providing the necessary level of support in emergency situations.