
With companies turning to hybrid infrastructure models with critical business applications running in the cloud, network resilience is more important than ever. During Hurricane Harvey, Houston customers congratulated us on network performance, saying “the network didn’t skip a beat.” Some have asked us what makes a network so resilient, especially during weather events like Harvey. It’s not only about having diverse, concrete encased network feeds and path diversity, it’s also about having visibility into the state of the Internet at any given moment. Our senior network engineer, William Knobles, explains more.
“Resiliency is about more than having multiple physical links. Although this is very important, it’s also about having visibility into both our own network and the greater Internet. Having visibility into the current state of the Internet allows us to proactively respond to issues and/or network events before they impact our customers. In the case of an event such as Hurricane Harvey, our network engineers actively monitor each of our varied transit providers and shift traffic as necessary to ensure a seamless end-user experience. Maintaining diverse transit connections ensures that our engineers are able to ‘route’ around potential traffic jams, accidents, and/or construction on the highways and byways of the Internet. This attention to detail is what has allowed Data Foundry to stand out.”
Diverse Pathing
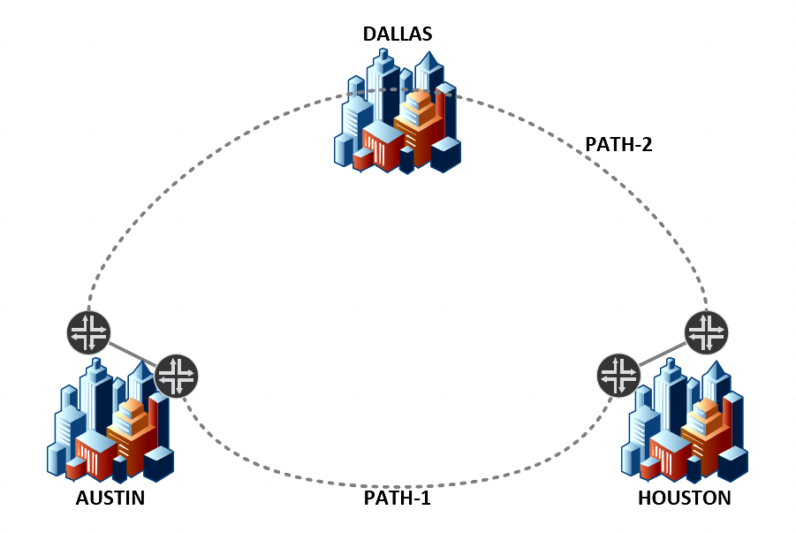
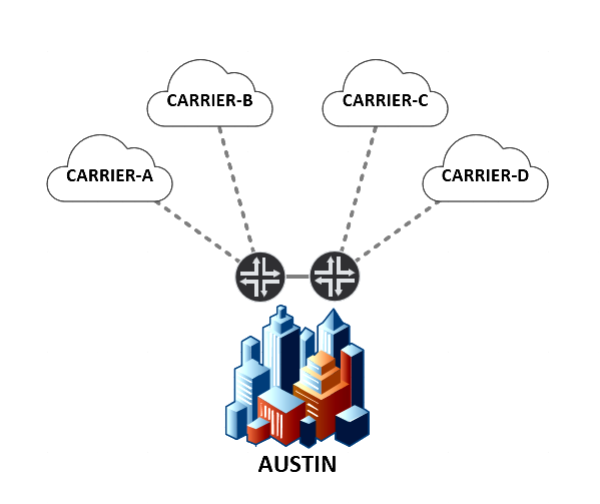
Diverse pathing provides redundancy by ensuring that the traffic for a given transit provider does not travel over the same physical fiber bundle as another provider. For example, to ensure that a single fiber cut does not affect traffic between Data Foundry’s Texas 1 and Houston 2 data centers, we maintain two diverse paths — one path going directly from Austin to Houston, and the other going from Austin, through Dallas, to Houston. This same focus on diversity is applied to our transit providers, with our engineers ensuring that different providers land to different physical devices follow different cable paths, and even enter the data center through different conduits.
Monitoring & Traffic Engineering
Monitoring and traffic engineering are also essential to maintaining network uptime. “Essentially, traffic engineering is a data-driven process wherein we analyze the health of our networks from both an inside-out and an outside-in viewpoint with the goal of continually providing a high-level of reachability to our customers to ensure their business-needs are being met,” says Knobles.
Monitoring the Internet is achieved using varied tools, but some of the most useful tools are reachability monitors. These can include outbound tests such as IP SLAs (IP Service Level Agreements) or RPMs (Real-Time Performance Monitors) which are configured on our network devices and are targeted to remote IPs/hosts out on the Internet. These types of tests allow our engineers to receive alerts if performance and/or reachability to a specific target begins to degrade, which then allows them to investigate further and identify the potential problem.
Inbound tests can also be configured from remote hosts on the Internet, (typically third-party solutions such as ThousandEyes, PingPlotter, StatusCake, etc.) and targeted to specific hosts and/or networks within Data Foundry’s environment. These tests can also provide alerts and ‘health’ checks on performance and reachability, which provide data to help our engineers make decisions on where and how to shift or route traffic.
In addition to being a colocation provider, Data Foundry has offered network and Internet services for over 20 years. Visit our network page to learn more.